可以利用微信来运维移动网络吗?机器学习如何拯救被动的无线网络?
我们每天用微信,社交网络在互联网信息传播中扮演着非常重要的角色。社交网络的普遍性、分布性与信息的全面性为我们网络分析提供了绝佳的入口。我们可以在机器学习的帮助下,利用用户社交网络关系,实现高效网络运维,完成从”被动型“网络向”主动型“网络的颠覆性转型。
1
什么是机器学习?
我们来看看两幅画:
这是莫奈的作品

这是梵高的作品

那么,我们现在再列举几张画,你能认出哪些是梵高的作品,哪些是莫奈的作品吗?
<1>

<2>

<3>

<4>

<5>

很明显,1、4、5是梵高的作品,2、3是莫奈的作品。
你是怎么区别出来的?
当你看到这些画的时候,你的脑子里已经有了一个“公式”:
莫奈的画:光色迷人,气象悠远,梦幻般的感觉,有一种女性的柔美。
梵高的画:色彩简单,激情燃烧,有一种男性的粗狂和力量。
这就是机器学习,向数据和经验”学习“,从中分析获得规律,再利用规律对未知数据进行预测。上图中,我们从两张画中获得了数据和经验,这叫训练集(train set) ;训练集用来估计模型,就像我们头脑中的”公式“,这叫测试集(test set);然后,我们就可以在测试集上做预测了,我们便能识别出后面5张莫奈和梵高的画。
移动通信网络内有大量的用户、数据流量,还有大量用户与网络之间的交互,以及大量用户与用户之间的交互,这些大数据就是机器学习现成的”资产“,我们能否用机器学习来预测用户行为,实现网络从”被动型“向”主动型“转变?
2
从“被动型”网络向“主动型”网络转型
很遗憾,从1G到4G,蜂窝通信技术发展到今天,依然是一个“被动型”的网络。只有用户发起了请求,网络才响应。
我们需要一个“主动型”的网络。
我们都说未来的网络是异构网络,网络内有宏蜂窝、微蜂窝、微微蜂窝、Small Cells等等各种节点,甚至还有终端设备和终端设备之间的连接,我们叫之为D2D通信(Device to Device)。这个网络是相当复杂的,多层的。如果网络不能从“被动型”向“主动型”转型,运维工作将相当繁琐。
更重要的是,流量海啸扑面而来,如果网络不能做到提前预测,提前缓存、疏导和均衡流量负载,这个网络不仅是低效的,而且是高成本的。
由于流量需求猛增,未来的基站内将配置缓存服务器,CDN(内容分发网络)技术将应用于无线网络,我们称之为无线CDN。
如何更好的在无线网络中应用CDN技术?我们可以通过统计流量模型和用户信息分析(比如,内容流行度、地理位置标签、移动速度和移动模型等),运用机器学习,来提前预测用户将向网络请求什么内容,并将内容提前缓存到用户所处的基站缓存服务器。
举个栗子。你正在追热剧《太阳的后裔》,昨晚在家里看了第一集,而根据网络分析,网络发现你习惯在办公室午休时看一集电视剧。于是,网络在凌晨就提前将《太阳的后裔》第二集缓存到你办公室所处的那个基站里。对于你来说,就近访问,速率快得惊人。对于网络来说,数据下沉到基站侧,不用通过回传访问核心网,减小网络负担。
我们如何才能预先知道用户要访问的内容呢?这需要一个全新的视角来看网络拓扑。
3
从用户的角度俯视网络
你有没有发现,这些网络用户的社交圈子所形成的网络拓扑,与我们蜂窝通信网的拓扑结构非常相似。一个大V带动很多粉丝形成一个社交圈子,就像一座基站带了很多用户终端一样。
我们把网络分为两层:里面一层是网络设备层,外面一层叫社交网络层。网络设备与设备之间是互相连接的,而外面的社交网络层中的用户之间也是相互连接的。两层之间提供交互接口,网络设备层向社交网络层学习,并预测用户行为来为用户提供服务,社交网络层提供网络学习的数据和模型。
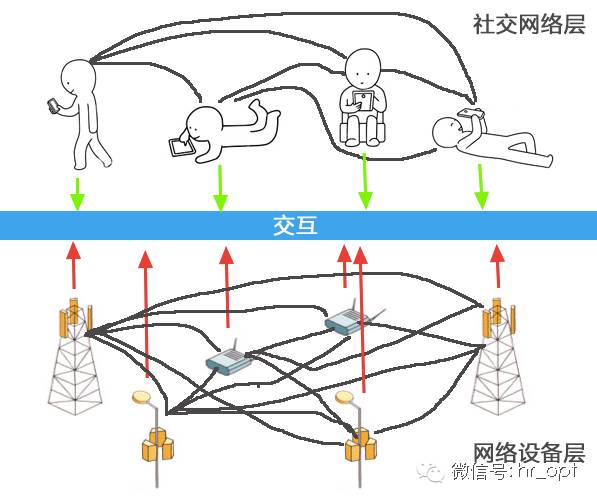
我们每天在微博、微信上晒图片,朋友与朋友之间分享、推荐电影和游戏等。人们通过社交网络聚在一起,形成了不同的社交圈子,这可对应机器学习中的聚类分析。我们可以通过这些网络社交圈子来建立关系模型,从中学习,来预测用户行为。
4
如何利用社交网络和机器学习预测用户行为?
首先,我们应该认识到机器学习+社交网络的必要性:
①对于单用户的大数据分析,由于数据量有限,不足以预测单用户行为。我们只有通过其社交圈子的海量用户数据来建立可靠的关系模型。
②对用户行为预测,机器学习尤为重要。为了减少网络预测失效,比如用户最终并没有访问预先缓存的内容,或者,用户的内容请求网络并未预测到,网络必须运用连续的机器学习来寻找最优模型。
现在,我们简单介绍运用机器学习方法来预测用户喜好的内容。
我们先举一个极端的例子。比如,某所大学有一个微信公众号,学生们都订阅了该微信公众号。某天,这个微信公众号发布了一篇介绍《太阳的后裔》这部电视剧。童鞋们都感兴趣,并且开始在朋友圈转发。接下来,校园里的童鞋们陆续用手机观看这部电视剧。
同时,网络从该公众号的历史行为学习到:每一次该公众号发布的内容都会引起童鞋们的追随。此时,网络就立即将该电视剧的内容直接缓存到大学附近的基站里,让用户就近访问内容,减小网络回传负担。
当然,不一定是微信公众号,也可能是某一个微博(或者未来的X博)的大V,这涉及到网络节点的Centrality(中心性) 概念,具体不深入探讨,小编也不懂。
再以协同过滤(Collaborative Filtering)算法为例。Netflix和Amazon一类的互联网公司,早就运用协同过滤(Collaborative Filtering)算法来为用户推荐影视和书籍。
协同过滤算法的基本思想是:
●和你兴趣合得来的朋友喜欢的,你也很有可能喜欢;
●喜欢一件东西A,而另一件东西B与这件十分相似,就很有可能喜欢B;
●大家都比较满意的,人人都追着抢的,我也就很有可能喜欢。
我们就可以根据社交网络的关系模型,运用协同过滤算法来推理、预测出用户将向网络请求的内容,将内容提前缓存到基站里。
在机器学习中,DP( Dirichlet Processes)里有一个响亮的名字Chinese Restaurant Process,即中国餐馆过程。
假设有一个中国餐馆,里面有很多桌子,中国人三五成群进来,由于中国人喜欢扎堆,专爱找桌上有人的地方去,若刚好有空位,就会选择扎堆坐下来。没有空位,就会新开一张桌子,后续进来的顾客同理。这其实就是一个聚类的过程。
后续进来的顾客在选择座位时,受到前面顾客已选座位的影响。我们说,这叫后进来的顾客从先入座的顾客那里”学习“并选择自己的座位。
餐馆就像是网络,内容就像是桌子,网络用户就是进入餐馆的中国顾客。用户向网络请求下载他们追捧的内容,当第一个用户下载了某一个内容,网络将此记录下来(称为历史)。第一个用户的行为将影响他所下载的内容被后续用户再次下载的概率。
…
其实,有很多大牛在研究这个,本文不过是管中窥豹而已。因昨日装X未遂,今天咬牙换了马甲继续装。
网优雇佣军投稿邮箱:[email protected]
长按二维码关注

通信路上,一起走!

文章评论