一、介绍
NodeJS 单线程、事件驱动的特性可以在单台机器上实现极大的吞吐量,非常适合写网络爬虫这种资源密集型的程序。
这段时间写了一个可以爬取知乎关系链的小爬虫,输入某个用户的用户主页 URL,就可以爬取他的关系链。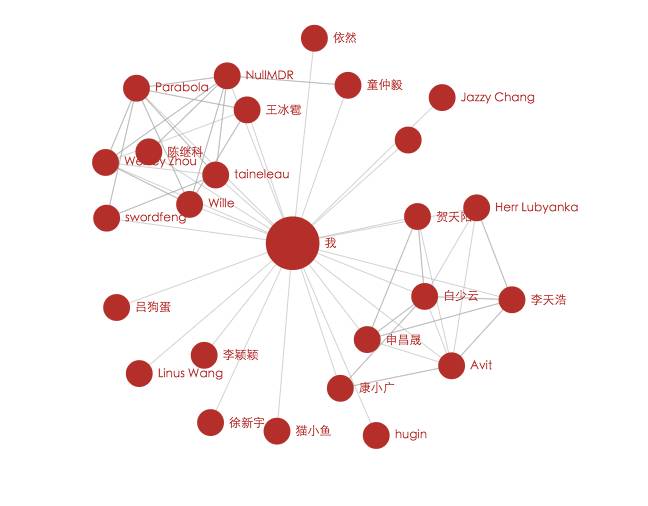
二、爬虫的实现
数据请求方面使用了 request 这个模块,用express响应请求,前端构图使用了 Echarts,中间数据交互是用 websocket 做的。
主要用到了知乎的两个 API:
//获取目标用户的关注者
POST https://www.zhihu.com/node/ProfileFollowersListV2
参数:
method:"next", //填入next即可
params:{
offset:40, //20的倍数,从0开始每次拉取20个关注者
order_by:"created", //填入"created"即可
hash_id:"d965f32a168564f9e58ad3a48a1585a4" //目标用户在知乎唯一的hash_id
},
_xsrf:"289c6ef5534d3dbb6a54057826864799" //xsrf参数,cookie中给定的//获取目标用户关注的人
POST https://www.zhihu.com/node/ProfileFolloweesListV2
参数:
method:"next", //填入next即可params:{
offset:40, //20的倍数,从0开始每次拉取20个关注的人
order_by:"created", //填入"created"即可
hash_id:"d965f32a168564f9e58ad3a48a1585a4" //目标用户在知乎唯一的hash_id
},
_xsrf:"289c6ef5534d3dbb6a54057826864799" //xsrf参数,cookie中给定的爬虫的工作流程如下:
-
获取目标用户的关注者、关注的人列表,找出和他相互关注的人(即朋友)
-
对朋友列表里的朋友重复1中的步骤,找出朋友的朋友列表
-
遍历 2 中的结果,找出朋友之间的相互关注关系、
三、部分代码
首先我们写一个getUser方法,它的作用是请求一个用户主页 URL,获取请求结果,解析出用户的昵称、hash_id、关注者数量、关注的人数量。
var request = require('request');
var Promise = require('bluebird');
var config = require('../config');
function getUser(userPageUrl) {
return new Promise(function(resolve, reject) {
request({
method: 'GET',
url: userPageUrl,
headers: {
'cookie': config.cookie
}
}, function(err, res, body) {
if (err) {
reject(err);
} else {
resolve(parse(body));
}
})
});
}
function parse(html) {
var user = {};
var reg1 = /data-name=\"current_people\">\[.*\"(\S*)\"\]<\/script>/g;
reg1.exec(html);
user.hash_id = RegExp.$1;
var reg2 = /关注了<\/span><br \/>\n<strong>(\d*)/g;
reg2.exec(html);
user.followeeAmount = parseInt(RegExp.$1);
var reg3 = /关注者<\/span><br \/>\n<strong>(\d*)/g;
reg3.exec(html);
user.followerAmount = parseInt(RegExp.$1);
var reg4 = /<title> (.*) - 知乎<\/title>/g
reg4.exec(html);
user.name = RegExp.$1;
return user;
}
module.exports = getUser;接下来需要一个fetchFollwerOrFollwee方法,它的作用是输入上面的 user 对象,根据在第二部分介绍的 API,抓取出用户的所有关注的人或者关注者,使用方法类似(使用 es6):
getUser('someURL')
.then(user => fetchFollwerOrFollwee({user: user, isFollowees: false})
.then(list => console.log(list))具体代码详见原文,就不贴上来了
接下来要做的就是组合getUser和fetchFollwerOrFollwee,变成一个getFriends方法,输入是用户页 URL,输出是用户的好友列表,大概像这样:
function getFriends(someURL){
getUser(someURL)
.then(user => fetchFollwerOrFollwee(...))
.then((followersList, follweesList) => findFriends(followersList, follweesList))
}然后我们可以封装一个最后的searchSameFriend方法,输入是某个 user 和一个好友列表 myFriends,输出是这个 user 的所有好友中,也在列表 myFriends 中的好友:
function searchSameFriend(user, myFriends){
return getFriends(user.url)
.then(user => findSameFriends(userFriends, myFriends))
.then(sameFriends => console.log(sameFriends))
}最后整个爬虫的 promise 流程大概是这样的:
function Spider(){
return getUser(URL)
.then(user => getFriends(user))
.then(userFriends =>
Promise.map(userFriends, friend => searchSameFriend(friend,userFriends))
)
}当然其中缺少了部分用 websocket 和前端数据交互的代码。
阅读原文 拥有更好的阅读体验。


文章评论